
CleanAndAdapt
Si vous êtes étranger à Python, une formation est disponible en cliquant ici .
Qu’est ce que c’est ?
Le “CleanAndAdapt” est un fichier en python, permettant de traiter les fichiers .csv afin que ces derniers soient cohérent avec la base de données “Collec-Science”.
Il va donc nettoyer les données en enlevant les caractères spéciaux, en remplaçant les accents et en corrigeant certaines erreurs qui ont pu être faite lors de l’insertion des données par rapport à ce qui est attendu.
Puis, il va acoller les identifiants certaines informations afin que “Collec-Science” prennent bien en compte les données qui vont être insérées.
Comment l’utiliser ?
Pour utiliser le “CleanAndAdapt”, il faut tout d’abord importer le fichier .csv dans le Jupyterlab, au même niveau que le fichier “CleanAndAdapt.ipynb”.
Attention: il faut que les séparateurs entre les données soient bien des “;”, et non des “,” ou des tabulations.
Une fois le fichier importé, il faut lancer le fichier “CleanAndAdapt.ipynb”.
Ensuite, il faut aller dans l’onglet “Cell>Run all”.
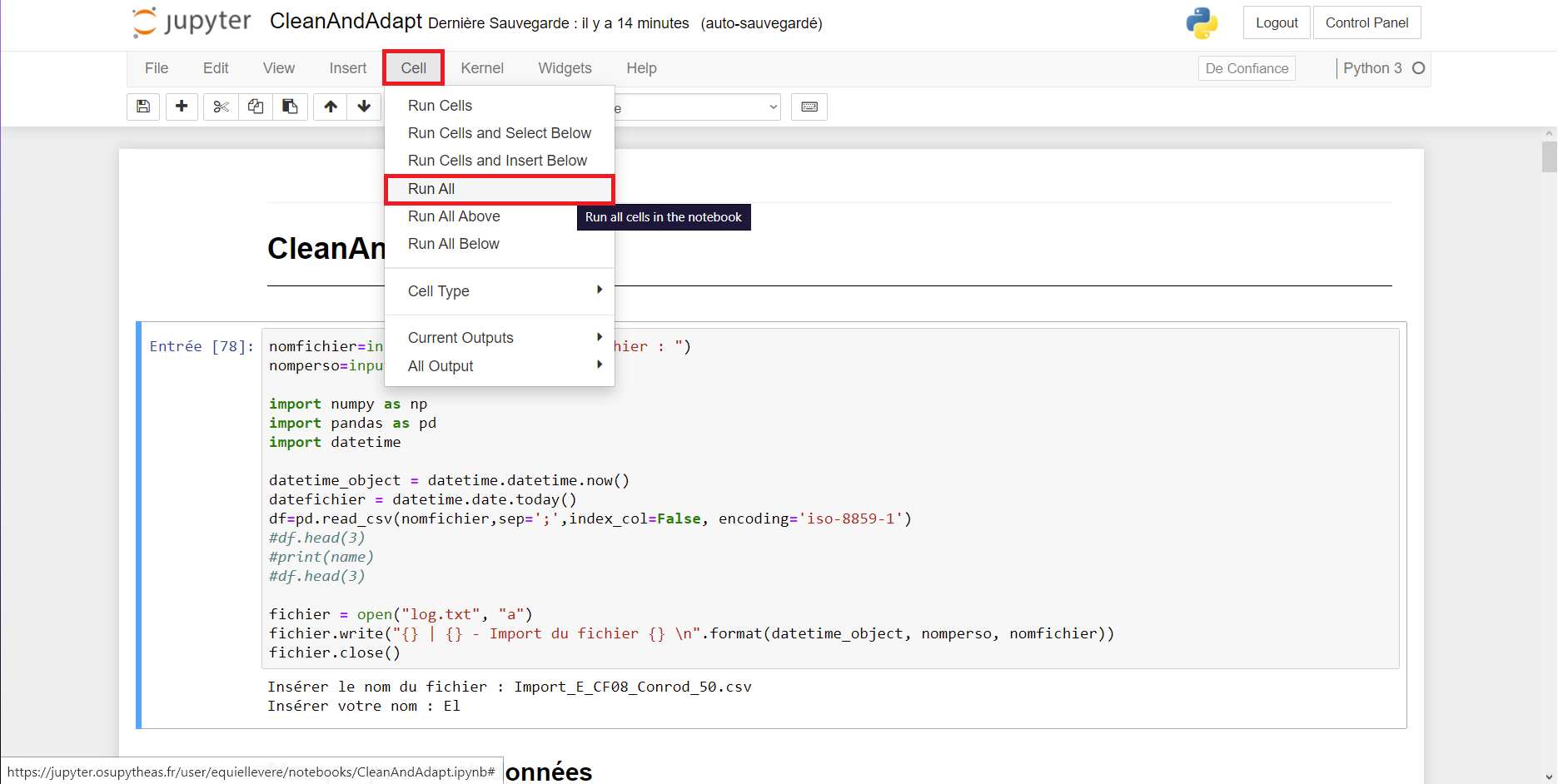
Deux zones de texte vont s’ouvrir:
– Dans la première, il faut insérer le nom de votre fichier .csv qui va être traité.
– Dans la seconde, il faut insérer votre nom pour pouvoir garder une trace du fichier, afin de savoir qui et quand est-ce que le fichier a été créé.
Une fois le traitement réalisé, un nouveau fichier csv va apparaître sous le nom de “{date}_{nom}-Echantillons.csv”.
Une fois le fichier créé, il faut le télécharger en sélectionnant le fichier et en appuyant sur “download”.
Le fichier est désormais prêt à l’import dans Collec-Science.
Note : Il peut subsister quelques erreurs si le fichier .csv de base à mal été interprété. Il faut donc vérifier le rendu pour voir si aucune incohérence est présente dans le fichier tout juste créer .